Six Experiments That Built My Intuition for Trust Bench
Before I could build a tool that profiles trust inside language models, I needed to understand what's happening inside them. These are the experiments that got me there.
I’m building Trust Bench, a tool that profiles trust signals inside language models. Not just output-level scoring, but extracting what’s happening in the activations, attention patterns, and internal representations that produce trustworthy or untrustworthy outputs.
Before I could build that, I needed to understand what’s actually inside these models. Not from papers. From running experiments myself.
Over the past few weeks I ran six targeted experiments, each one answering a question I needed answered before writing the next piece of Trust Bench. This post is the compressed version: what I ran, what I found, and why it mattered for what I’m building.
1. Watching superposition emerge
The question: Trust Bench needs to extract interpretable features from model activations. But if models store more features than they have dimensions (superposition), individual neurons won’t map to individual concepts. How bad is this problem, and when does it kick in?
I reproduced the key results from Anthropic’s Toy Models of Superposition in about 30 lines of PyTorch. A linear encoder compresses 10 features through a 5-dimensional bottleneck with a ReLU, and a tied decoder reconstructs the original.
The variable that matters is sparsity. At sparsity 0.0 (all features active), the model faithfully represents only 4 of the 10 features. At sparsity 0.9, it packs in 5 or more, tolerating the interference because sparse features rarely collide.
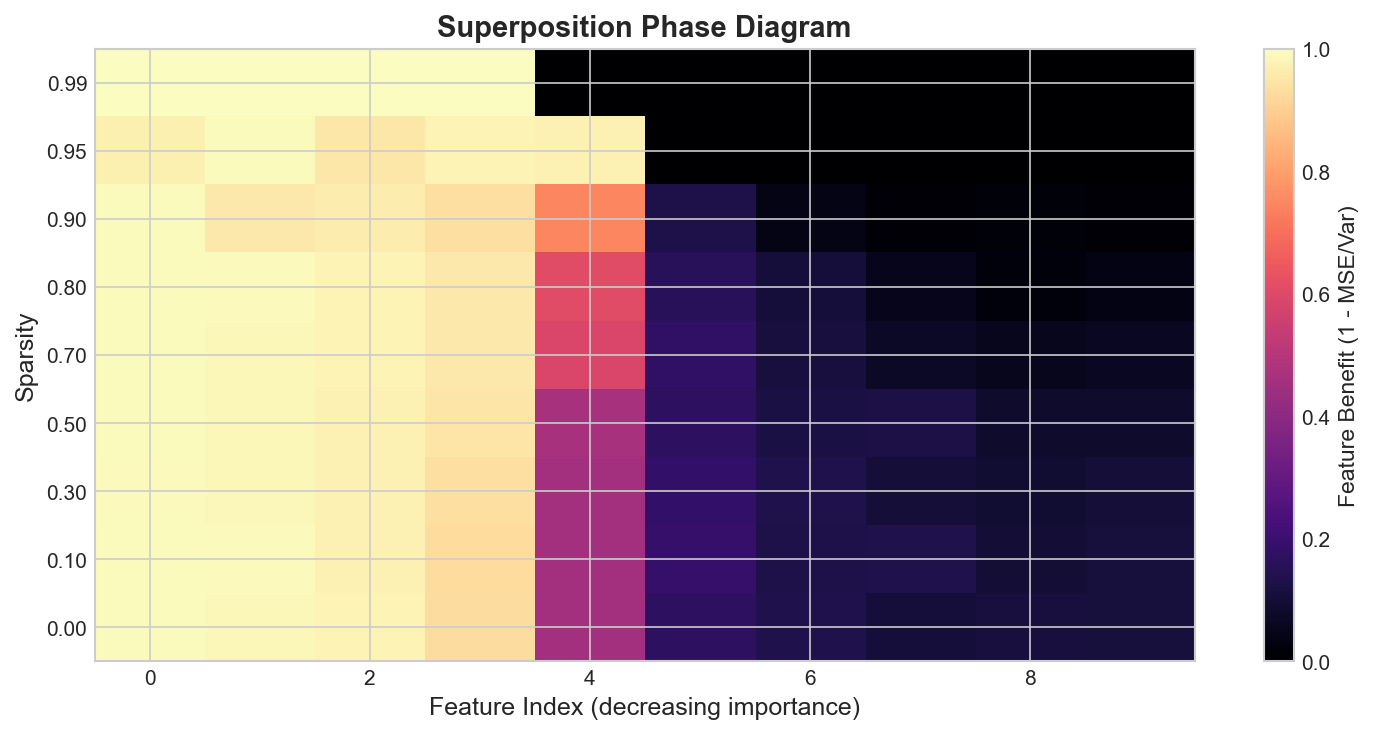
What surprised me: The transition is sharp, not gradual. Around sparsity 0.7, the model jumps from 4 represented features to 5. It’s a phase transition, not a smooth tradeoff. Below the threshold, the model doesn’t bother. Above it, it commits.
Why this matters for Trust Bench: If trust-relevant features (confidence, uncertainty, deception markers) are sparse, they’re likely stored in superposition. Trust Bench can’t just read individual neurons. It needs sparse autoencoders or similar decomposition to extract them. This experiment confirmed that the decomposition step isn’t optional.
2. How representations evolve through layers
The question: Trust Bench will extract signals at multiple layers. But which layers carry which information? Where does class-discriminative structure emerge?
I hooked into every layer of a CNN trained on FashionMNIST, extracted activations for 5,000 test images, and projected them to 2D with UMAP.
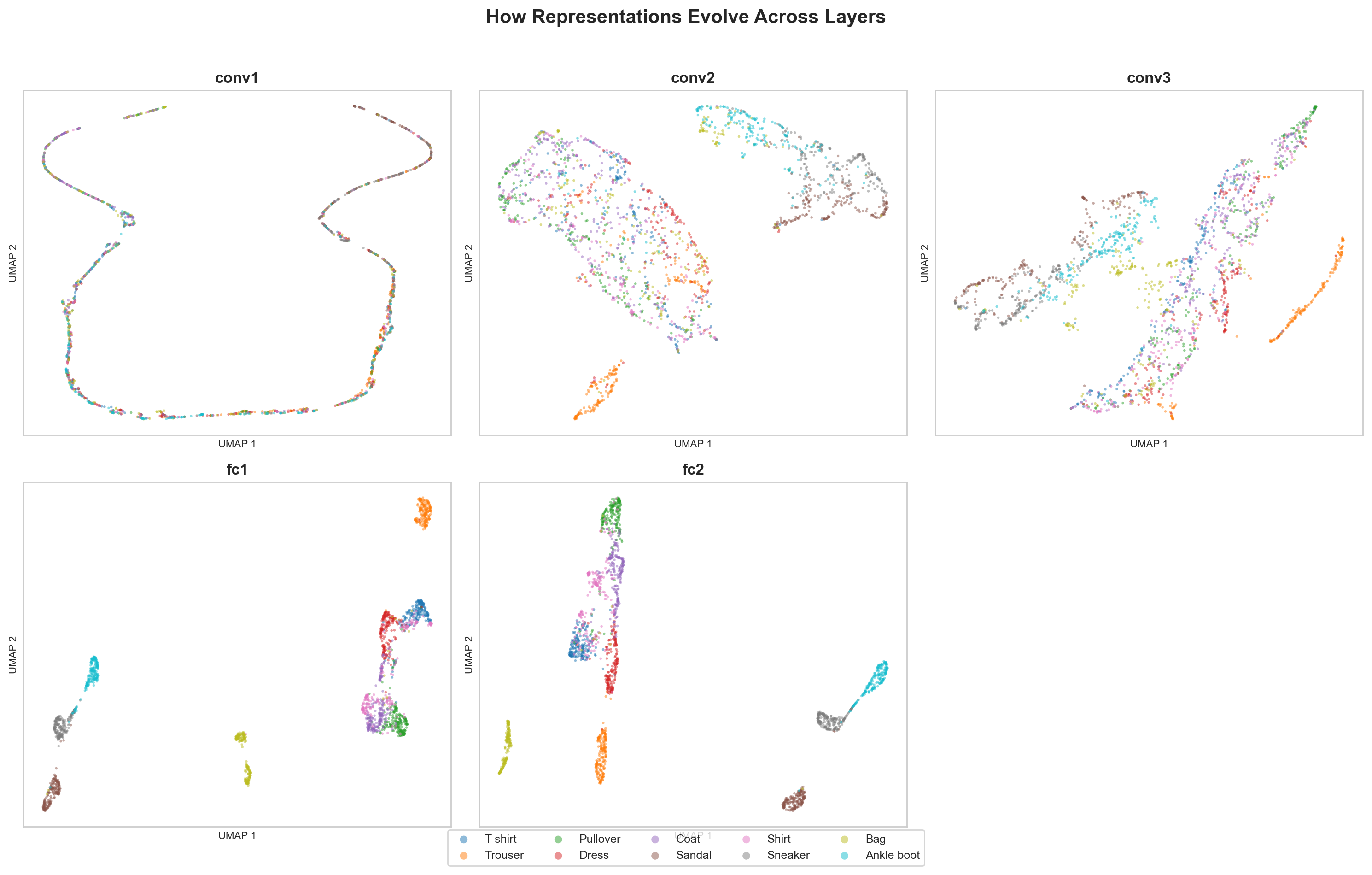
Early layers: a diffuse cloud, all classes on top of each other. By the final FC layer: ten tight clusters, mostly separated. PCA tells the same story through variance concentration. Early layers spread variance across many components. Late layers compress into a handful of directions.
What surprised me: The confusable pairs (T-shirt vs. shirt, pullover vs. coat) separate last but remain neighbors. The network learned to distinguish them AND learned they’re related. That’s exactly the structure you’d want.
Why this matters for Trust Bench: Trust signals probably live in middle-to-late layers, where representations have moved past surface tokens but haven’t committed to final predictions. This is where Anthropic’s SAE work focuses too. Trust Bench’s extraction hooks should prioritize these layers, not waste compute on early ones.
3. What the loss landscape reveals about robustness
The question: A model that sits in a sharp minimum is fragile. Small perturbations to weights cause large jumps in loss. If Trust Bench is going to apply targeted fixes (RepE steering, calibration adjustments), will the model stay stable after the intervention?
I trained MLPs on FashionMNIST with different hyperparameters, then visualized the loss surface around the trained weights using filter-normalized perturbations along two random directions.
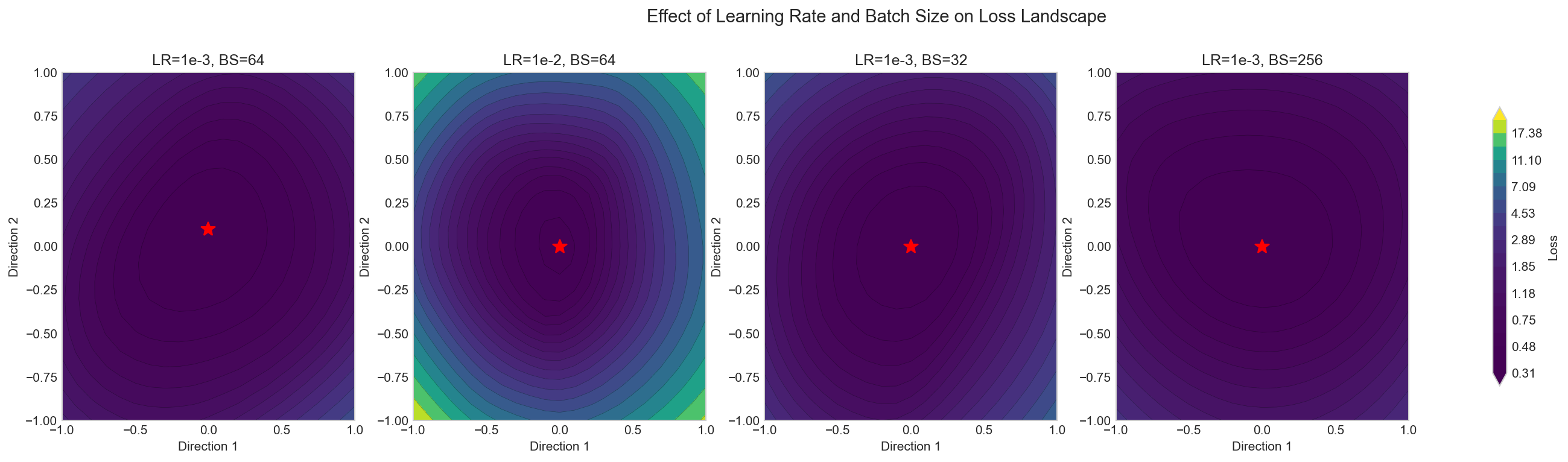
What surprised me: Learning rate and batch size control landscape geometry more than I expected. High LR with small batches produces the flattest basins. The LR bounces out of sharp minima, and gradient noise from small batches destabilizes narrow valleys. The effect is visible and quantifiable.
Why this matters for Trust Bench: When Trust Bench applies interventions (activation steering, post-hoc calibration), it’s perturbing the model’s effective weights. Models in flat minima will tolerate these perturbations. Models in sharp minima will break. The landscape shape predicts intervention stability. This might become a pre-check before Trust Bench applies any fix.
4. Do scaling laws hold at the sizes I can afford?
The question: Trust Bench starts with small models (Qwen3.5 at 0.8B, or smaller variants). I need to know if results at small scale predict anything about larger models. If the loss curve is unpredictable at toy scale, my experiments won’t generalize.
I trained five decoder-only transformers on TinyStories, spanning 100K to 10M parameters. Same architecture, same training setup, only model size varies. Then I fitted the Chinchilla power law: L(N) = a * N^(-b) + c.
| Model | d_model | Layers | ~Params |
|---|---|---|---|
| 100K | 64 | 2 | ~100K |
| 500K | 128 | 3 | ~500K |
| 1M | 192 | 4 | ~1M |
| 3M | 256 | 6 | ~3M |
| 10M | 384 | 8 | ~10M |
What surprised me: The power law fits. Five data points, high R-squared, all five sitting on the curve. I expected TinyStories might be too narrow a domain for scaling behavior to emerge. But even on children’s stories, each jump in parameters buys something, and the rate follows the curve. The irreducible loss floor c is lower than web-corpus estimates, which makes sense. Children’s stories are more predictable than the internet.
Why this matters for Trust Bench: I can run trust profiling experiments at small scale and have some confidence that the patterns will hold when scaling up. The power law means the relationship between capacity and behavior is smooth, not chaotic. Small-model Trust Bench results are directionally useful, not just noise.
5. Four attention variants, from scratch
The question: Qwen3.5 uses grouped query attention (GQA). Trust Bench needs to compare trust signals across attention types. Before I can do that, I need to understand what each variant actually computes at the tensor level.
I implemented MHA, GQA, MQA, and Sliding Window attention from scratch in PyTorch, no nn.MultiheadAttention. Each plugs into the same 6-layer decoder-only transformer, trains on TinyStories with identical hyperparameters.
The parameter differences are concrete. For d_model=256, n_heads=8:
- MHA: Q, K, V each 256x256. ~262K attention params per layer.
- GQA (4 KV heads): K, V drop to 256x128. Saves ~65K per layer.
- MQA (1 KV head): K, V drop to 256x32. Saves ~115K per layer.
- SWA: Same params as MHA. Savings come from compute, not parameters.
What surprised me: MQA is trivially derived from GQA. The entire class is three lines that set n_kv_heads=1. The implementation simplicity hides the fact that all query heads now share one key-value representation, which can measurably hurt quality at small scale. At Llama 3’s scale the gap closes.
Why this matters for Trust Bench: When Trust Bench extracts attention patterns from Qwen3.5’s hybrid architecture, it needs to handle GQA layers differently from full attention layers. The shared KV heads mean attention entropy and pattern diversity will look different in GQA layers, not because the model is less trustworthy, but because the attention computation is structurally different. Trust Bench needs to normalize for this, or it will confuse architecture effects with trust signals.
6. The experiment that tied it together
These five experiments gave me the foundation. Superposition told me I need SAE decomposition. Activation projections told me which layers to focus on. Loss landscapes told me about intervention stability. Scaling laws told me small-scale results are directionally useful. Attention variants told me how to handle Qwen3.5’s hybrid architecture.
The next step was training Qwen3.5 itself. That experiment, the one where I found a numerical bug that looked like a hyperparameter problem and spent 25 minutes watching a dead model, is its own post.
All the code
Each experiment is a standalone repo. Run it, read it, fork it.
| Experiment | Repo |
|---|---|
| Superposition | superposition-viz |
| Activation projections | activation-atlas |
| Loss landscape | loss-landscape |
| Scaling laws | scaling-laws |
| Attention variants | attention-bench |