A Single Neuron for 'And' in Six Languages
Using Gemma Scope's pre-trained sparse autoencoders to find cross-lingual features in Gemma 2 2B. Feature #10543 fires on 'and', 'et', 'und', 'y', and 'e' with zero activation on control sentences.
Trust Bench needs to extract interpretable features from model activations. The experiments I’ve been running showed me that superposition makes individual neurons unreliable, so I need sparse autoencoders to decompose activations into meaningful features.
Before I build that into Trust Bench, I wanted to understand what SAE features actually look like in a real model. Specifically: if I decompose a multilingual model’s activations, do I find features that represent concepts across languages? Or does each language get its own features?
This matters for Trust Bench because if safety-relevant concepts (deception, harmful intent, refusal) are stored in language-independent features, monitoring a small set of features might generalize across all languages. If they’re language-specific, that’s a concrete alignment concern.
I used Google’s Gemma Scope pre-trained SAEs to find out.
Setup
Gemma Scope provides pre-trained JumpReLU sparse autoencoders for every layer of Gemma 2 2B. Each SAE decomposes the 2304-dimensional residual stream into 16,384 sparse features. The idea, from Anthropic’s Scaling Monosemanticity work, is that individual neurons are polysemantic (they respond to many unrelated things), but SAE features can be monosemantic (each responds to one interpretable concept).
I loaded the layer 12 SAE using SAELens, ran 31 diverse prompts through Gemma 2 2B, and recorded which features fired on which tokens. Layer 12 sits in the middle of the 26-layer model, where representations have moved past surface-level token identity but haven’t yet committed to final predictions. My activation projection experiments pointed me toward middle layers for exactly this reason.
Finding the conjunction feature
The initial survey ran prompts across 13 categories: math, code, English/French/German/Spanish prose, safety, science, emotion, negation, numbers, temporal, and abstract reasoning. 11,009 unique features fired across these prompts.
Most high-firing features turned out to be unselective. Feature #2620 fires on nearly every content token. Feature #2291 fires on punctuation and common words regardless of category. These features are doing something (likely tracking position, sentence structure, or general “this is natural language” signals), but they are not monosemantic in an interesting way.
The interesting features are the narrow ones. I filtered for features that fire on few unique tokens but fire consistently, then probed them with targeted inputs.
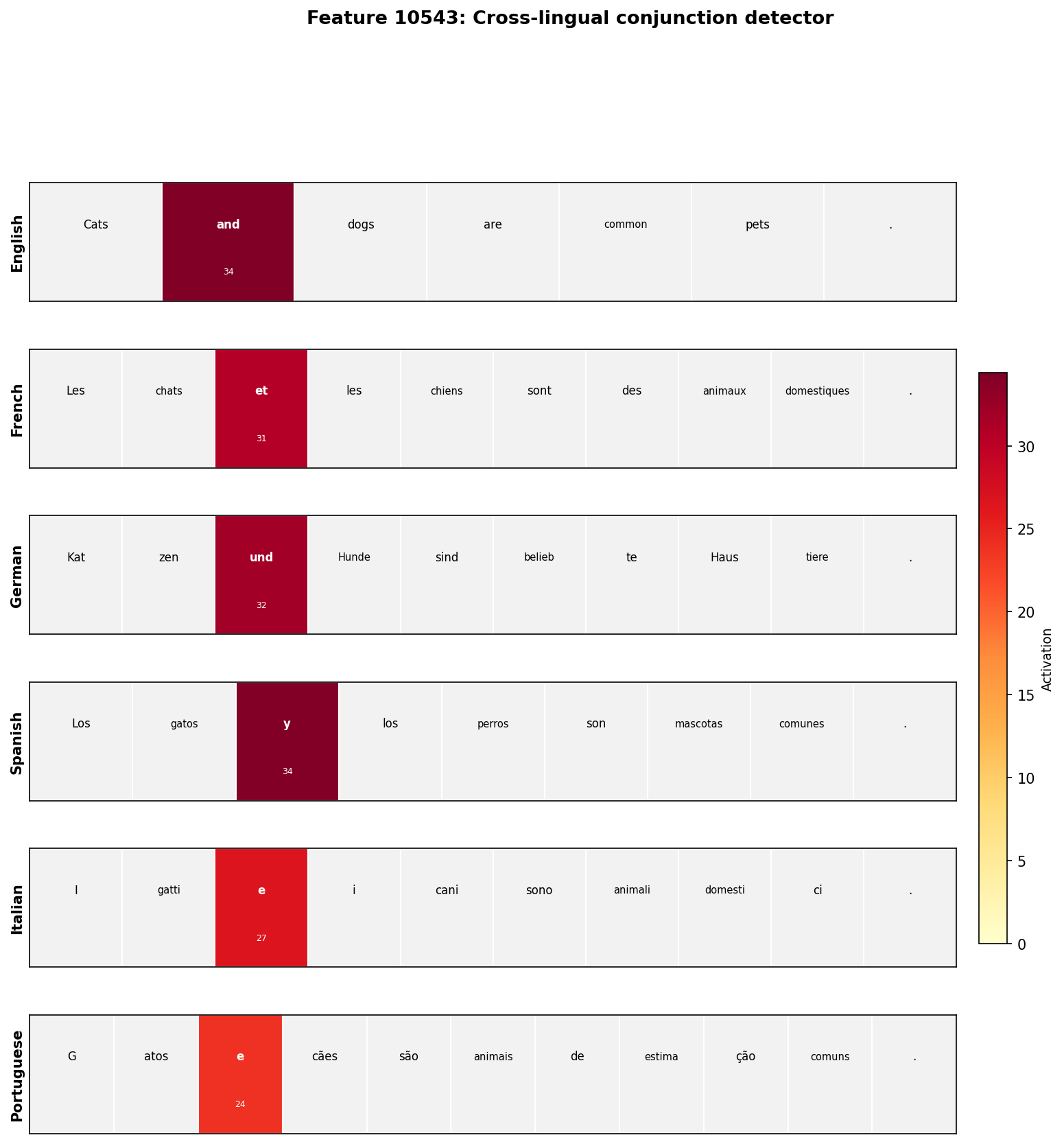
Feature #10543 stood out immediately. In the survey, it appeared in the “narrow features” list with just three token types: ’ und’, ’ et’, ’ and’. Those are the conjunction words for “and” in German, French, and English.
Verification
I tested Feature #10543 on 24 sentences across 6 languages, each containing a conjunction. It fired on every single conjunction token. Then I tested it on 6 control sentences without conjunctions. It fired on nothing.
| Language | Conjunction | Activation | Control activation |
|---|---|---|---|
| English | ”and” | 34.4 | 0.0 |
| French | ”et” | 30.7 | 0.0 |
| German | ”und” | 31.9 | 0.0 |
| Spanish | ”y” | 34.0 | 0.0 |
| Italian | ”e” | 27.0 | 0.0 |
| Portuguese | ”e” | 24.0 | 0.0 |
Average activation on conjunction sentences: 26.6. Average activation on control sentences: 0.0. The selectivity is binary.
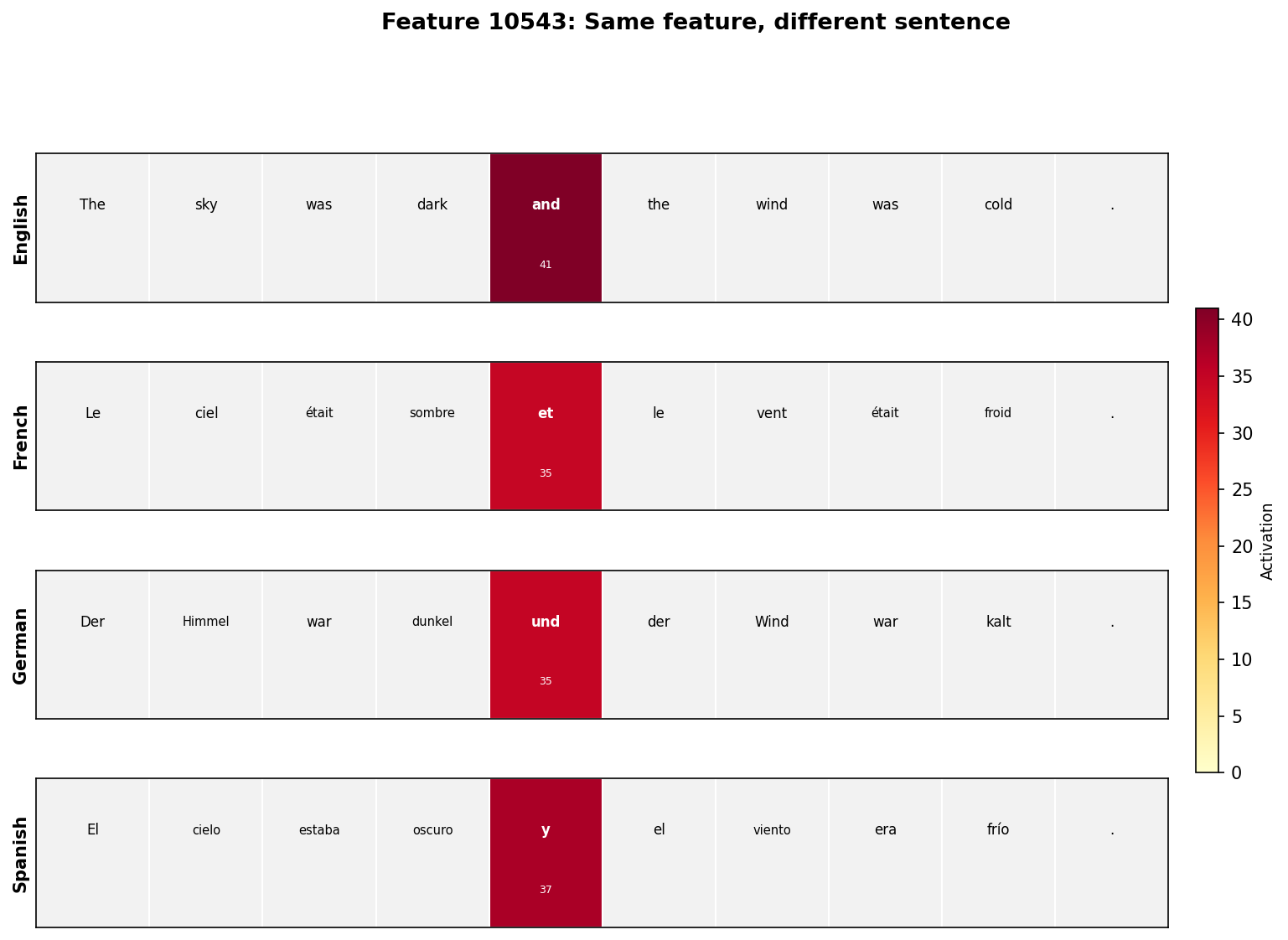
The same feature, different sentence:
Other cross-lingual features
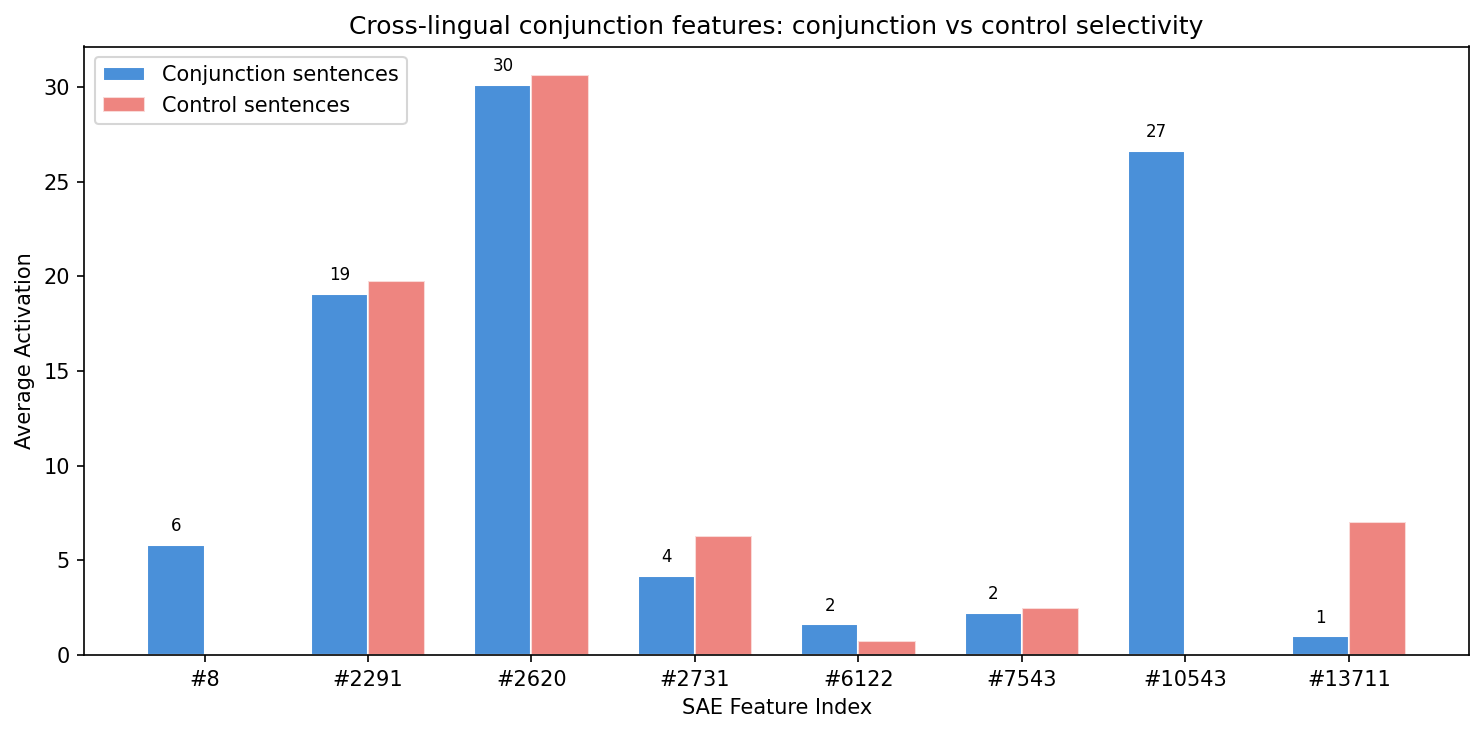
The conjunction feature is not unique. The broader search found 631 features that fire across 4+ languages on parallel sentences.
Feature #4497 is a cross-lingual “cat” feature. It fires on ’ cat’ (English), ’ chat’ (French), ’ Katze’ (German), ’ gatto’ (Italian), ’ gato’ (Spanish and Portuguese). Six different surface forms, one feature.
Feature #1178 detects sentence-initial determiners and pronouns across languages: ‘The’/‘She’ in English, ‘Le’/‘La’/‘Elle’ in French, ‘Die’/‘Das’/‘Sie’ in German, ‘El’/‘La’/‘Ella’ in Spanish.
Feature #2987 responds to domestic objects, firing on translations of “mat”, “water”, “house”, and “morning” across all six languages.
By layer 12, Gemma 2 2B has organized its representations around language-independent concepts. The model does not maintain separate “English and” and “French et” representations. It has converged on a shared abstraction that captures the grammatical role regardless of surface form.
What this means for Trust Bench
Feature #10543 is not just “correlated with conjunctions.” It has a threshold (the JumpReLU activation function), it fires with similar magnitude across languages (24-34 units), and it is silent on everything else. This is a discrete computational unit that the model uses when processing conjunctions, regardless of which language it is processing.
The question I started with was whether safety-relevant features would be language-independent. This experiment doesn’t answer that directly, but it shows the mechanism exists. Concrete concepts get stored as language-independent features. If deception or harmful intent follow the same pattern, then Trust Bench’s feature monitoring could generalize across languages. If they don’t, that’s a finding too, and it means Trust Bench needs per-language safety profiles.
The next step is finding features that correlate with trust-relevant behaviors: hedging, overconfidence, refusal, factual grounding. That’s what Trust Bench’s extraction stage is designed to do.
Debugging note
The initial survey showed 5,015 features firing at every token position. These all turned out to be BOS (beginning-of-sequence) features responding to the <bos> token, not to content. Feature #1041 fires at activation 1436 on BOS regardless of what follows.
This was caused by a tokenization bug: model.to_str_tokens() in TransformerLens returns the full text as a single string for Gemma 2, not individual token strings. Using model.tokenizer.decode(t.item()) per token fixed the alignment.
Half the work was debugging the tools, not the model.
Try it
git clone https://github.com/amaljithkuttamath/sae-explorer.git
cd sae-explorer
python -m venv .venv && source .venv/bin/activate
pip install -r requirements.txt
python probe_crosslingual.pyRequires ~10GB RAM (Gemma 2 2B + SAE). Runs on Apple Silicon via MPS or CPU.